Table of Contents
- Demo
- IP + port abstraction
- netlib API
- Client-side prediction and server reconciliation
- Implementation
- Next article
Welcome to the third article of the Fast-Paced Multiplayer Implementation series.
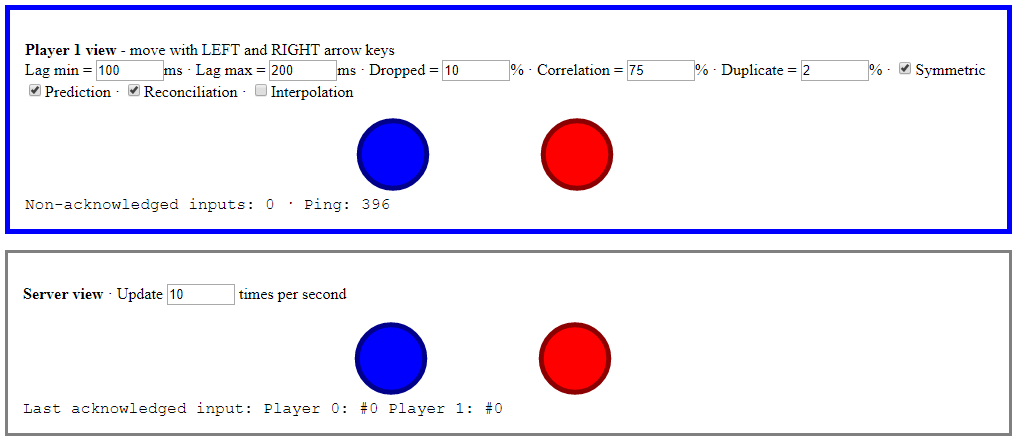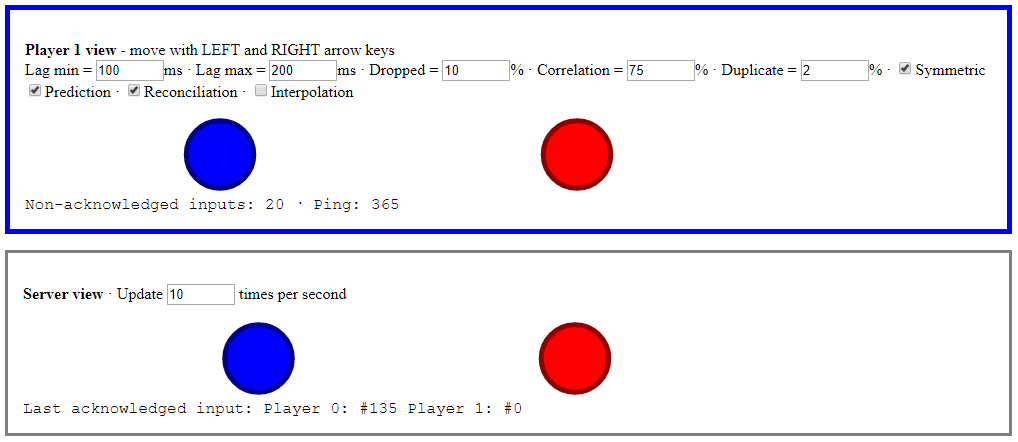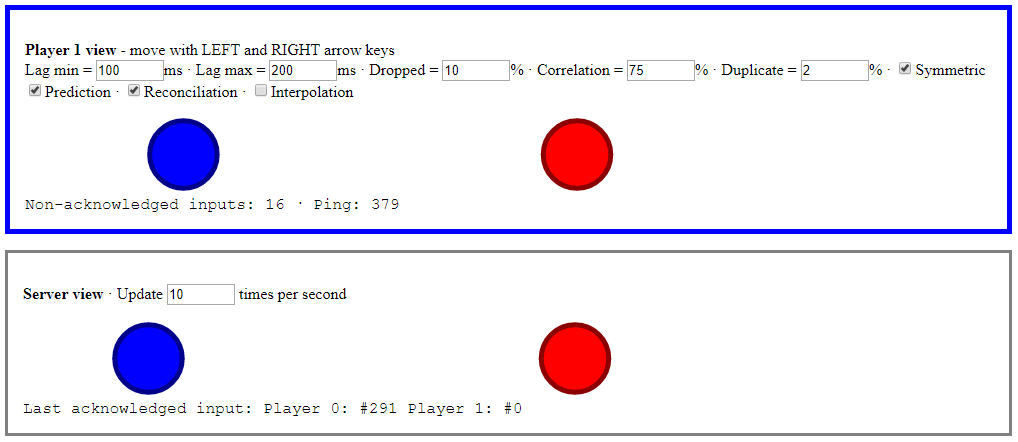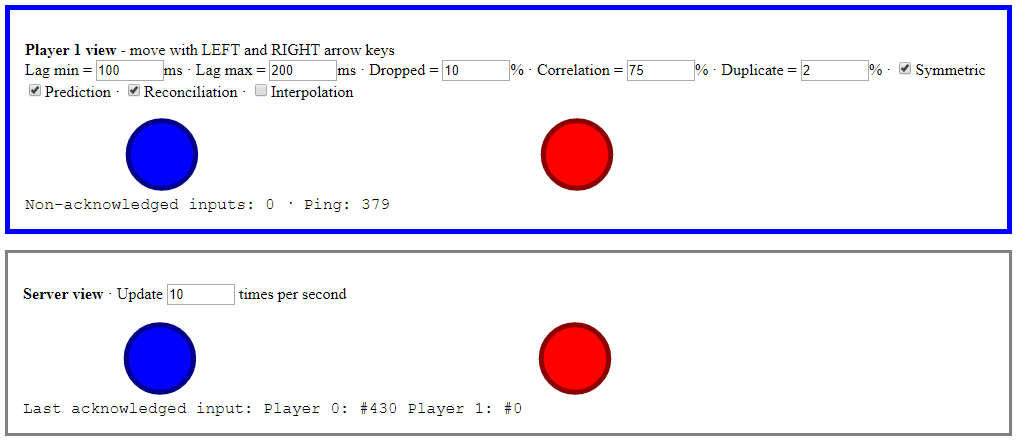
In this article I’ll discuss my minimalist reliable UDP library implementation, and how the message delivery types it provides improve the demo’s client-side prediction and server reconciliation.
Demo
Here’s the demo: https://fouramgames.com/posts/netlib/main.html (Chrome recommended). The source is in the usual repository, in the netlib branch.
Note that remote entity interpolation isn’t yet at its full potential - it will be the subject of a later article.
IP + port abstraction
In real world UDP sockets send packets to other sockets. Simply put, sockets are identified by an IP address (v4 or v6) which identifies the host machine and a port number (an almost arbitrary number) which identifies the application on that host.
This is a topic in itself, so for the demo I just assigned a unique integer to each host and used that as an abstraction instead.
netlib API
In a moment of inspiration I decided to name my library netlib.
Here’s a basic diagram of the public-facing API. For the sake of conciseness some features and types haven’t been included.

Using netlib in an application makes the update loop look like this:
- Receive packets from a lower layer, and pass them to
enqueueRecv(msg: any, from: NetAddress, curTimestamp: int), at which point netlib processes them, and may discard or hold them. - Obtain and process the received messages from
getRecvBuffer(): Array<NetIncomingMessage>. - Execute the usual update loop (simulating physics, etc), during which messages are sent using
enqueueSend(msg: NetMessage, toID: int, curTimestamp: int). - Obtain the messages to send to every peer using
getSendBuffer(toID: int, curTimestamp: int): Array<any>and pass them to a lower layer.
In the demo’s case the lower network layer is the network model that was introduced in the first article. It’s a black box from netlib’s point of view.
Here’s an example of sending an input from client to server:
this.netHost.enqueueSend(new NetReliableOrderedMessage(input), this.serverPeerID, curTimestamp);
This API isn’t very different from ENet or RakNet at this high abstraction layer. So while I’ll use netlib for subsequent articles and demos, it won’t stop someone using a real networking library from finding them useful.
Client-side prediction and server reconciliation
Nothing has significantly changed on the server side. The world state is still sent as an unreliable message.
When the client receives a world state message however, it checks that its sequence ID is newer than the previous one. This has the effect of dropping late messages.
The client also now sends its inputs as reliable ordered messages.
That’s all there is to it. This is of course easily reproducible using other reliable UDP libraries.
Implementation
I used Glenn Fiedler’s articles on reliable UDP (Reliability and Congestion Avoidance over UDP and Reliable Ordered Messages) as references. I had also spent some time using ENet before so I drew inspiration from it for designing the API.
Below are some interesting tidbits I gathered while writing my library.
Heartbeat messages
When providing the option to send unreliable or reliable messages, it’s easy to forget that only reliable messages carry acks. This means that if a host only sends unreliable message it will never acknowledge the peers’ messages, and the protocol would break.
My solution was to send a dummy reliable “heartbeat” message containing only the latest acks to peers if no other up to date reliable message was sent that frame. This is done every time getSendBuffer is called, a possible improvement would be to let the rate be user-configurable.
Message round-trip time and drop rate are also only measured on reliable messages (using acks), so that’s another reason why heartbeats are necessary.
Re-transmission strategy
I looked at how other libraries and protocols do it for inspiration (Yojimbo, ENet, TCP). At some point in the future I’ll write about the inner workings of a few of them.
I settled on a really simple method. I assume that it theoretically takes exactly a round-trip time to receive an ack for a sent message. In practice I estimate that a message is lost if its ack is not received within a period of RTT + RTT variance * 2.
If I detect a lost message, I resend it with a new sequence ID. I also include the original sequence ID in it so that the recipient can avoid forwarding duplicate packets to the user. The recipient still sends an ack for a duplicate resent message though, or else the sender will keep re-transmitting it forever.
This is extremely reliable, but the fact that a lost message is only re-transmitted after a timeout period incurs unacceptable latency. We can reduce this delay by sending redundant messages at the cost of bandwidth.
While the message is in a limbo state (sent but RTT not yet elapsed), we can re-send the message a few times at a certain rate. This can be included as an optional setting for very time sensitive packets such as client inputs. Chat messages for example can do without.
Let’s pretend that we’re transmitting client inputs (reliable ordered) over an average connection:
- RTT is 200ms
- RTT variance is 20ms
- Packet loss is 2%
- Because it’s an ordered message stream, a lost message stalls the entire stream. This is extremely undesirable.
Messages would usually take 200ms / 2 = 100ms to arrive at their destination. Using only timeout re-transmissions, there would be a 2% chance of stalling the stream for 200ms + 20ms * 2 = 240ms (message takes 340ms to arrive). At a rate of 60 messages per second, that would happen 60 * 0.02 = 1.2 times a second, or once every 1 / 1.2 = 0.8 seconds. Unacceptable!
Let’s add redundant re-transmissions (100ms intervals) and look at the distribution of the time it would take for messages to arrive at their destination:
- ~98% - 100ms
- 2% (once every 0.8s) - 200ms
- 0.04% (once every 42s) - 300ms
- 0.0008% (once every 34 minutes) - 340ms
Let’s see how much the redundancy costs in bandwidth:
- 98% of the sent messages would get through on their first delivery attempt.
- 98% of their acks would also get through on their first delivery attempt.
- So 96% of the sent messages take RTT +/- RTT variance = [180ms, 220ms] to get acked.
- I’ll guess it means that in this case we will have sent 1.5 redundant messages for each one while waiting for its ack.
We would then be using 250% the usual bandwidth 96% of the time. Game clients often send only input messages which are very small in size, so the redundancy can be dialed up significantly (with respect to the available bandwidth of course).
Pardon the napkin math. I hope it still manages to illustrate well the trade-offs of the redundant re-transmission strategy.
Buffers
All buffers are implemented as circular arrays, per Glenn’s recommendation. There’s conceptually four buffers per peer in netlib:
- Buffer to discard received duplicate messages
- Buffer of the messages sent
- Buffer of received reliable or reliable ordered messages (the acks we’ll send to the peer)
- Buffer to hold and re-order reliable ordered messages
The size of these buffers determines the robustness of the protocols. It’s a matter of balancing robustness against network throughput (in the case of the acks) and robustness against memory for the rest.
Errors, timeout, and disconnection
netlib notifies an event handler when any assumption in the protocols is broken. Given reasonable buffer sizes, this only happens in extremely terrible connections. The default netlib handler for these errors disconnects the peer outright but the user may choose what to do depending on the error. netlib also generates timeout events.
A netlib host sends an unreliable disconnection message when disconnecting a peer. On reception the peer disconnects himself silently and notifies an event handler.
ENet does this better and sends the disconnection message as a reliable message and waits for acknowledgment (with a timeout).
Connection
There’s no connection protocol, it’s simply simulated by manipulating the objects directly in the JS runtime.
The road to production
I may revisit netlib in the future but it will probably just remain something I made out of necessity for use in a simulated network in a browser environment. Dissecting ENet/RakNet/Yojimbo’s code would provide more interesting content than further work on netlib.
Here are the many missing features necessary for deployment in a real game:
- Use 16-bit integers where possible and handle the wrap-around
- Use more efficient packet headers
- Connection establishment protocol
- More precise measurements of ping and drop rate
- Packet fragmentation and message aggregation for MTU
- Flow control and congestion avoidance
- Logical channels
- Message priorities
- Security
- Testing and optimization
Next article
The next article returns to discussing application-level logic instead of UDP and the network layer. It’s about smoothing server reconciliation to prevent jarring visual artifacts when the client and server states diverge.
You can subscribe to the mailing list to be notified when a new article appears.