Table of Contents
Source code
As I mentioned in my post about migrating to Jekyll, I made a Python console tool for upgrading all possible HTTP links to HTTPS in a Jekyll blog. This post will discuss its implementation.
Here is its source code for reference: https://github.com/Ohmnivore/https_sentry
Use cases
First use case (check health)
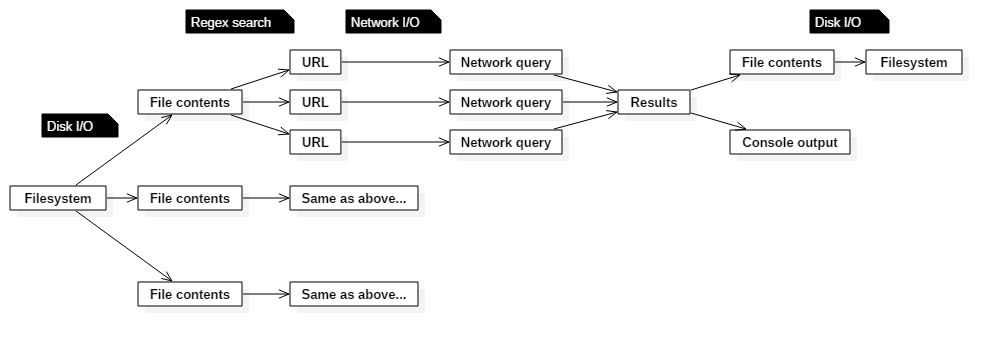
- For each file in a specified directory: find all the contained URLs of a specified protocol
- For each found URL: try to reach the URL and report any errors on failure
Second use case (upgrade protocol)
- For each file in a specified directory: find all the contained URLs of a specified protocol
- For each found URL: replace its protocol by the desired upgrade protocol (ex: from HTTP to HTTPS)
- For each replaced URL: try to reach the URL and report any errors on failure
- On success, replace the original URL in the file by the one that uses the upgrade protocol
Performance
Dead simple approach
My first approach was to simply execute all the steps synchronously. This was slow. The bottleneck were, by far, the blocking network requests.
Data flow
Let’s take a look at how the application transforms data:
Multithreading
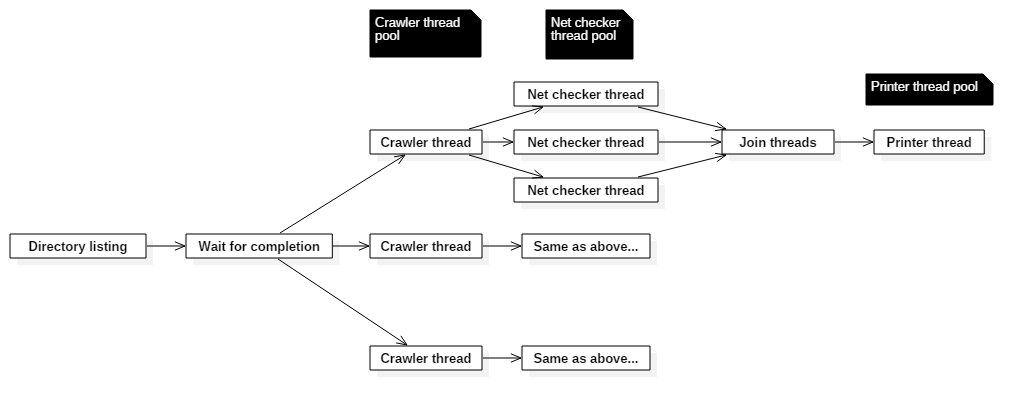
There’s a few data manipulations that can be done in parallel:
- Crawler threads: Reading files, and then searching them for URLs can be done using one thread per file
- Net checker threads: URLs can be queried using one thread per URL
- Printer threads: Saving results to a file and printing output to console can be done using one thread per file
It would be possible to also spread the URL regex search across multiple threads but I decided not to. It would only be beneficial for unreasonably long files. The use of multithreading for disk I/O is already an extravagance with little benefit (aside from network filesystems maybe?). But it was fun to make!
The multithreaded logic looks like this:
Python GIL
Let’s address the elephant in the room: Python (in its vanilla form) has a global interpreter lock. Simply put, it means that Python doesn’t interpret code simultaneously in multiple threads. Instead it rapidly switches thread contexts in between blocking I/O operations.
This is terrible of course if an application’s bottleneck is its interpretation/execution. But most often I/O operations are the bottleneck by a large margin (as is the case with https_sentry). In times like these the GIL is really a non-issue. The added safety of the GIL also allows me to not shoot myself in the foot with multithreading. All in all it’s something I can live with.
Implementation details
There’s a global URL cache. A net checker thread inserts its URL into the cache before launching its network request. Other net checker threads that are tasked with the same URL will either wait for the results or simply grab them if they’re already available.
Net checker threads that are waiting on another thread to process their common URL notify their thread pool scheduler of the fact. The scheduler will expand the pool capacity for the duration of the waiting thread, as the waiting thread isn’t really putting any load on the system’s resources.
Printer threads consume results in the alpha-numerical order of the original file directory traversal. This is done with a priority queue by waiting until the next expected entry in the sequence appears at its head.
There’s no function in the Python PriorityQueue API for peeking the head element of a queue. To emulate it I actually pop the head element and push it back if it’s not what I needed. That’s probably terrible, yet insignificant in the larger scope of the application.
Possible improvements
It could use some automated tests, and docstrings everywhere. Oh and a better way to peek a PriorityQueue.
It could also use existing Python multithreading APIs like events and conditions for the producer/consumer logic instead of just polling every millisecond.
I also barely dipped my feet in the ocean that is concurrency. I would be interested to explore a method that automatically determines the amount of threads for each producer/consumer that would allow optimal data flow through this pipeline. Asking the user to guess these amounts (which to be fair is a very common approach) isn’t great.
Regardless, it now only takes me a few seconds to run https_sentry for my entire blog. It used to take more than a minute with the synchronous approach.